1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
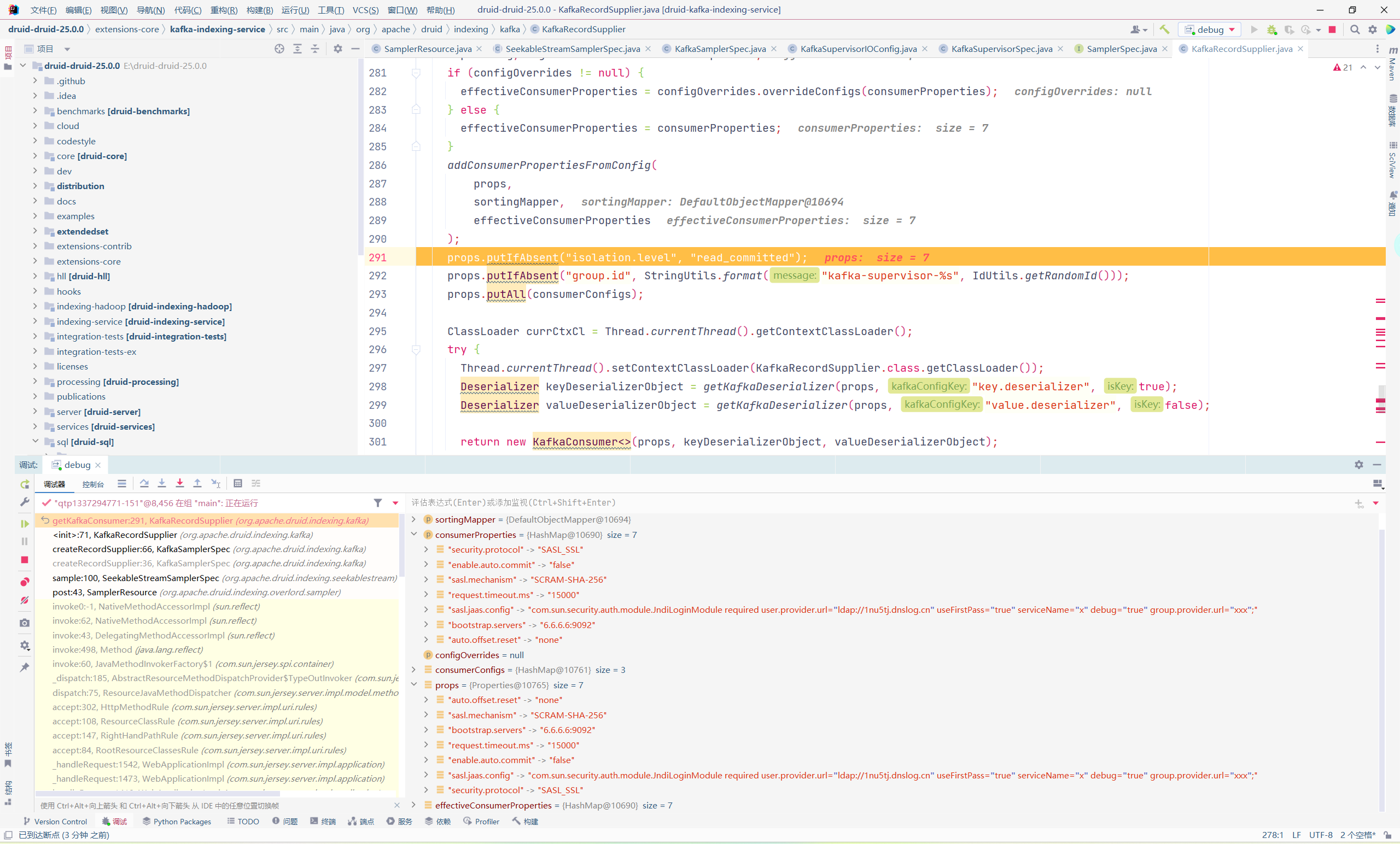
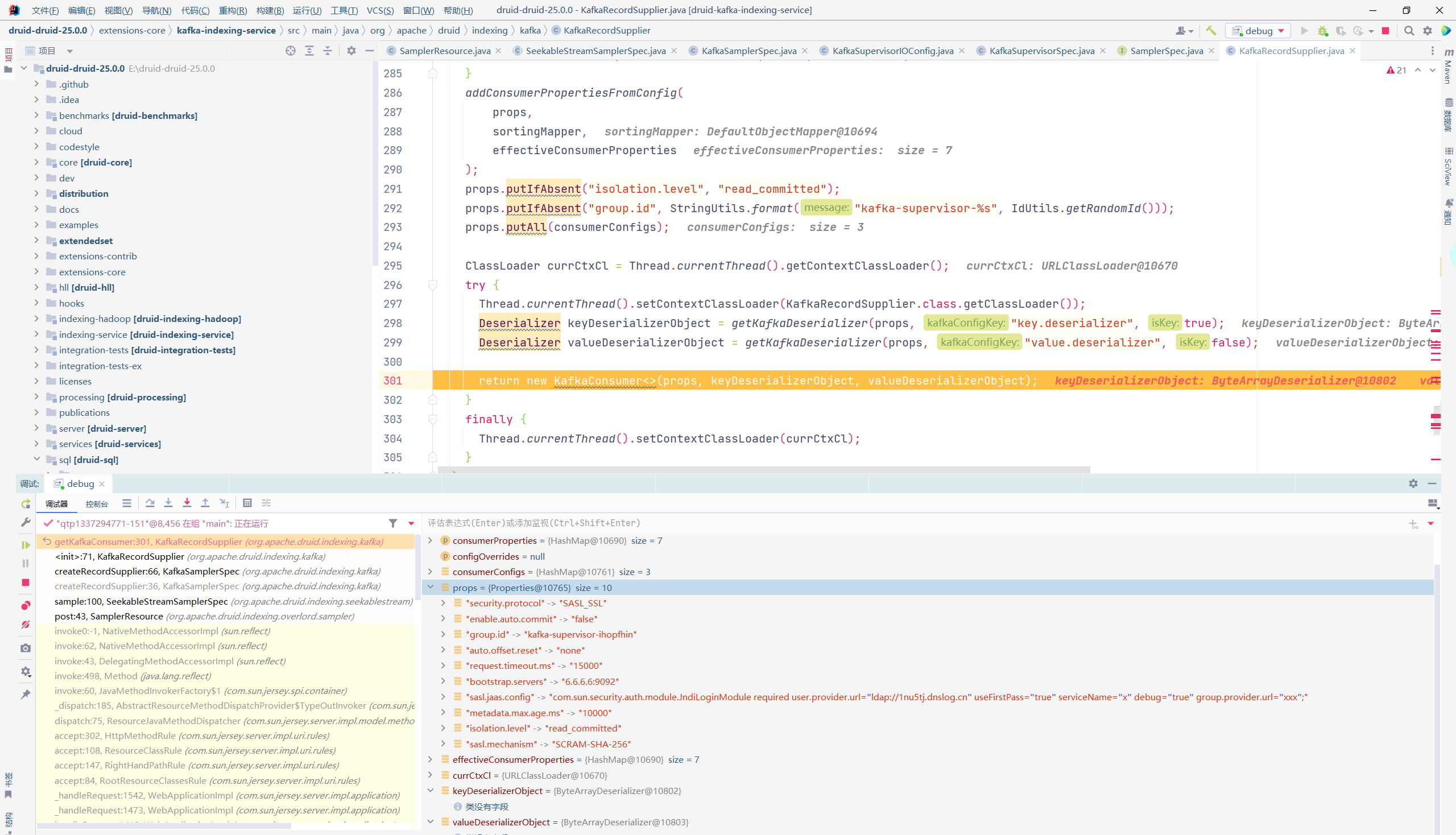
| public KafkaConsumer(Map<String, Object> configs) {
this((Map)configs, (Deserializer)null, (Deserializer)null);
}
public KafkaConsumer(Properties properties) {
this((Properties)properties, (Deserializer)null, (Deserializer)null);
}
public KafkaConsumer(Properties properties, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
this(Utils.propsToMap(properties), keyDeserializer, valueDeserializer);
}
public KafkaConsumer(Map<String, Object> configs, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
this(new ConsumerConfig(ConsumerConfig.appendDeserializerToConfig(configs, keyDeserializer, valueDeserializer)), keyDeserializer, valueDeserializer);
}
KafkaConsumer(ConsumerConfig config, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) {
this.closed = false;
this.currentThread = new AtomicLong(-1L);
this.refcount = new AtomicInteger(0);
try {
GroupRebalanceConfig groupRebalanceConfig = new GroupRebalanceConfig(config, ProtocolType.CONSUMER);
this.groupId = Optional.ofNullable(groupRebalanceConfig.groupId);
this.clientId = config.getString("client.id");
LogContext logContext;
if (groupRebalanceConfig.groupInstanceId.isPresent()) {
logContext = new LogContext("[Consumer instanceId=" + (String)groupRebalanceConfig.groupInstanceId.get() + ", clientId=" + this.clientId + ", groupId=" + (String)this.groupId.orElse("null") + "] ");
} else {
logContext = new LogContext("[Consumer clientId=" + this.clientId + ", groupId=" + (String)this.groupId.orElse("null") + "] ");
}
this.log = logContext.logger(this.getClass());
boolean enableAutoCommit = config.maybeOverrideEnableAutoCommit();
this.groupId.ifPresent((groupIdStr) -> {
if (groupIdStr.isEmpty()) {
this.log.warn("Support for using the empty group id by consumers is deprecated and will be removed in the next major release.");
}
});
this.log.debug("Initializing the Kafka consumer");
this.requestTimeoutMs = (long)config.getInt("request.timeout.ms");
this.defaultApiTimeoutMs = config.getInt("default.api.timeout.ms");
this.time = Time.SYSTEM;
this.metrics = buildMetrics(config, this.time, this.clientId);
this.retryBackoffMs = config.getLong("retry.backoff.ms");
List<ConsumerInterceptor<K, V>> interceptorList = config.getConfiguredInstances("interceptor.classes", ConsumerInterceptor.class, Collections.singletonMap("client.id", this.clientId));
this.interceptors = new ConsumerInterceptors(interceptorList);
if (keyDeserializer == null) {
this.keyDeserializer = (Deserializer)config.getConfiguredInstance("key.deserializer", Deserializer.class);
this.keyDeserializer.configure(config.originals(Collections.singletonMap("client.id", this.clientId)), true);
} else {
config.ignore("key.deserializer");
this.keyDeserializer = keyDeserializer;
}
if (valueDeserializer == null) {
this.valueDeserializer = (Deserializer)config.getConfiguredInstance("value.deserializer", Deserializer.class);
this.valueDeserializer.configure(config.originals(Collections.singletonMap("client.id", this.clientId)), false);
} else {
config.ignore("value.deserializer");
this.valueDeserializer = valueDeserializer;
}
OffsetResetStrategy offsetResetStrategy = OffsetResetStrategy.valueOf(config.getString("auto.offset.reset").toUpperCase(Locale.ROOT));
this.subscriptions = new SubscriptionState(logContext, offsetResetStrategy);
ClusterResourceListeners clusterResourceListeners = this.configureClusterResourceListeners(keyDeserializer, valueDeserializer, this.metrics.reporters(), interceptorList);
this.metadata = new ConsumerMetadata(this.retryBackoffMs, config.getLong("metadata.max.age.ms"), !config.getBoolean("exclude.internal.topics"), config.getBoolean("allow.auto.create.topics"), this.subscriptions, logContext, clusterResourceListeners);
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config.getList("bootstrap.servers"), config.getString("client.dns.lookup"));
this.metadata.bootstrap(addresses);
String metricGrpPrefix = "consumer";
FetcherMetricsRegistry metricsRegistry = new FetcherMetricsRegistry(Collections.singleton("client-id"), metricGrpPrefix);
ChannelBuilder channelBuilder = ClientUtils.createChannelBuilder(config, this.time, logContext);
this.isolationLevel = IsolationLevel.valueOf(config.getString("isolation.level").toUpperCase(Locale.ROOT));
Sensor throttleTimeSensor = Fetcher.throttleTimeSensor(this.metrics, metricsRegistry);
int heartbeatIntervalMs = config.getInt("heartbeat.interval.ms");
ApiVersions apiVersions = new ApiVersions();
NetworkClient netClient = new NetworkClient(new Selector(config.getLong("connections.max.idle.ms"), this.metrics, this.time, metricGrpPrefix, channelBuilder, logContext), this.metadata, this.clientId, 100, config.getLong("reconnect.backoff.ms"), config.getLong("reconnect.backoff.max.ms"), config.getInt("send.buffer.bytes"), config.getInt("receive.buffer.bytes"), config.getInt("request.timeout.ms"), config.getLong("socket.connection.setup.timeout.ms"), config.getLong("socket.connection.setup.timeout.max.ms"), this.time, true, apiVersions, throttleTimeSensor, logContext);
......
} catch (Throwable var18) {
if (this.log != null) {
this.close(0L, true);
}
throw new KafkaException("Failed to construct kafka consumer", var18);
}
}
|